When you wait until the last minute to deal with database changes, schema comparison is one of the tools necessary to reverse engineer what changed in your database. A schema comparison helps identify what changed about the structure of the database. For example, a table was added or a column was removed. Schema comparison doesn’t focus on what may or may not have changed with the data in the tables.
Imagine walking down a street of tract housing, where every house was built alike.

Tract housing, identical homes
These homes start the same both inside and out. If someone adds a sun-room, it would be quite noticeable from the outside. By examining the structure, you could detect a difference. If, someone threw out all the original appliances and bought new ones, that would require going inside to see what might have changed. Kind of like when data is altered.
When you feed your development and production database, or for that matter any two databases, through a schema comparison you can determine the differences between the two.
From those differences, it’s possible to reverse engineer what changed. Schema comparison tools are known to generate a set of scripts to synchronize the databases. Usually you have the choice of what to do to merge the differences. You could change either database to synchronize them. Though in the case of development and production, most likely you’re trying to recreate the changes applied to development, so you can apply them to production when you release the next version of your application.
How precise is this?
But the process of reverse engineering isn’t precise. It would be as if someone else on the block wanted to replicate the sun-room. They could go study the sun-room and try to recreate it. They may come close, but chances are they won’t replicate the exact same sun-room. Now in the case of a sun-room, that may not matter. In fact it might be desirable to be unique. But in the case of databases, we need to ensure the changes are the same.
Because schema comparison isn’t an exact science, there’s a need to manually review the proposed changes to synchronize the databases. The nature of each change, and the amount of cumulative changes will dictate the difficulty in recreating the changes in another database.
Three styles of changes come to mind:
- Additive – only add to the schema of the database
- Subtractive – only remove from the schema of the database
- Both additive and subtractive
If all you ever do is add to your schema, a comparison tool will have no trouble reconciling the differences automatically. It simply needs to create the new structures in your production database. You can add tables or columns to existing tables. The only trouble is in adding these in the appropriate order as what you add may have dependencies to what else is being added.
Similarly, if all you ever do is remove things, a schema comparison tool will have no trouble reconciling the differences automatically. The only trouble is in removing things in the proper order. The second you start adding things, all bets are off.
Chances are you can’t rely on 100% additive nor 100% subtractive changes. You’ll get both, especially when you wait a long time to reconcile differences. Like when you wait until a release to compare differences. In these situations, you need to review the proposed changes. For example:
- Even independent additive and subtractive changes can lead to problems when they pile up. If months pass between releases, you might drop a column that was unused and then several weeks later, add a new column with the same name for another purpose. In a comparison this will go unnoticed.
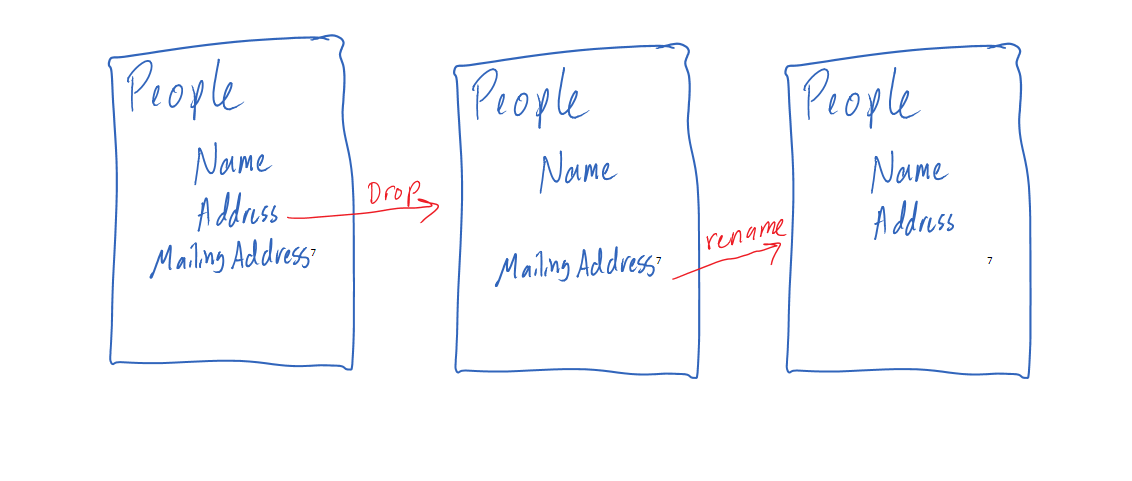
- When you get into more advanced transformations, or you pile up many changes, interesting things happen. Let’s say you have a table of People with Name, Address and MailingAddress columns. Let’s say one week you realize Address isn’t used by the application, so you decide to drop it. Several months later someone renames MailingAddress to just Address. Maybe because you have no reason to track any other type of address. After both changes, a comparison tool will recommend simply dropping the MailingAddress column. It’s the most logical guess as to what happened. It’s what you would probably propose if you looked at the comparison results yourself. Maybe the person that performs the comparison remembers hearing that you dropped an address column and they sign off on the migration. How long would it be before you find out? This would deploy just fine and could exist for months if nobody notices.
These problems are fundamental to comparison. Comparison can detect differences, but it can’t tell you with certainty how those differences arose. The more complex the changes, the more possible paths. And the path often matters. At best, a tool can make an educated guess about the path. And this is true whether you use a tool to compare and reverse engineer, or whether you do it by hand. Actually, the tool is more likely to get it right. Think about that for a minute.
Therefore comparison cannot reverse engineer the changes with certainty. You have to review what’s proposed and do the detective work to ensure that’s what actually happened. With small changes, you can patch a proposed SQL script or toggle what’s generated if the tool supports that. But, even after a few changes, the resulting SQL scripts will make your eyes bleed. Complexity of the proposed scripts also tends to be proportional to the complexity of your database. Just take any comparison tool for a spin after making a few changes to a database.
The reality is, mistakes are going to happen. It’s just a matter of time.
Blueprints
If you want to clone a sun-room, you will probably make an effort to hunt down the blueprints of the original.
You do this when you review proposed changes to your database too. Maybe you hunt down the individuals that made the change. Maybe you’re lucky and they remember what they did. Maybe they saved the script they used to change the development database. But chances are they don’t remember and didn’t save the script. And if you have them re-create their change, they may make a mistake too.
No matter what you do, if you don’t have a process to save changes when they happen, you can’t be guaranteed to recreate them with certainty.
When to compare
Reverse engineering with certainty is inversely proportional to the amount and complexity of changes. And the more time that lapses, the more changes you probably have. But comparison tools work well with smaller changes and shorter periods of time. They serve as great detective tools while you’re making changes.
Perhaps you like the tools you normally use to change your database. You can continue to use those tools. When you’re done, you can use a comparison tool to produce a list of what you need to review. If a few hours have lapsed, chances are what you did is fresh in your mind. Here’s how you can leverage this workflow to your advantage:
- Backup your database, preferably you have a personal development database that you don’t share with others.
- Make changes, play with different ways you might want to change your database. Evolve your changes by making them and then looking at the result.
- Use whatever tool you want to make the changes. I recommend a tool that can detect and correct dependencies, a database refactoring tool.
- Even better, write tests as you change your database to ensure your application still behaves as expected. Or, use existing tests. Refactor your database while re-running these tests and making sure they continue to pass.
- Once you’re happy with the changes, run a comparison versus the backup. Spin up a second database from the backup if your comparison tool can’t use a backup as a source of comparison.
- Look at the differences. Look at the proposed SQL script. Consider what you might have missed. Use a tool to look at the dependencies of what you changed. Determine if your changes are satisfactory. Ask someone to review your changes, someone with advanced database knowledge.
- Create a script to capture the changes.
- Drop the changed database (make an extra backup if you want to be safe)
- Restore the from your backup when you started
- Run your change script
- Run your tests
- Run the comparison again and see if the differences match, obviously the proposed SQL change script might not.
- Check everything into version control including the change script. Make a folder called SQL, name the file, put some comments about it into your commit message. You’ll be leaving a history of what, why, who, when and how.
This is one of many workflows you can create if you keep in mind the benefits of detecting differences and balance the reality of reverse engineering the path that led to those differences.
2 comments for “What database schema comparisons can accomplish”